Publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
-
 One More Modality: Does Abstract Meaning Representation Benefit Visual Question Answering?Abhidip Bhattacharyya, Emma Markle, and Shira WeinIn Findings of the Association for Computational Linguistics: EMNLP 2025, Nov 2025
One More Modality: Does Abstract Meaning Representation Benefit Visual Question Answering?Abhidip Bhattacharyya, Emma Markle, and Shira WeinIn Findings of the Association for Computational Linguistics: EMNLP 2025, Nov 2025Visual Question Answering (VQA) requires a vision-language model to reason over both visual and textual inputs to answer questions about images. In this work, we investigate whether incorporating explicit semantic information, in the form of Abstract Meaning Representation (AMR) graphs, can enhance model performance—particularly in low-resource settings where training data is limited. We augment two vision-language models, LXMERT and BLIP-2, with sentence- and document-level AMRs and evaluate their performance under both full and reduced training data conditions. Our findings show that in well-resourced settings, models (in particular the smaller LXMERT) are negatively impacted by incorporating AMR without specialized training. However, in low-resource settings, AMR proves beneficial: LXMERT achieves up to a 13.1% relative gain using sentence-level AMRs. These results suggest that while addition of AMR can lower the performance in some settings, in a low-resource setting AMR can serve as a useful semantic prior, especially for lower-capacity models trained on limited data.
2024
-
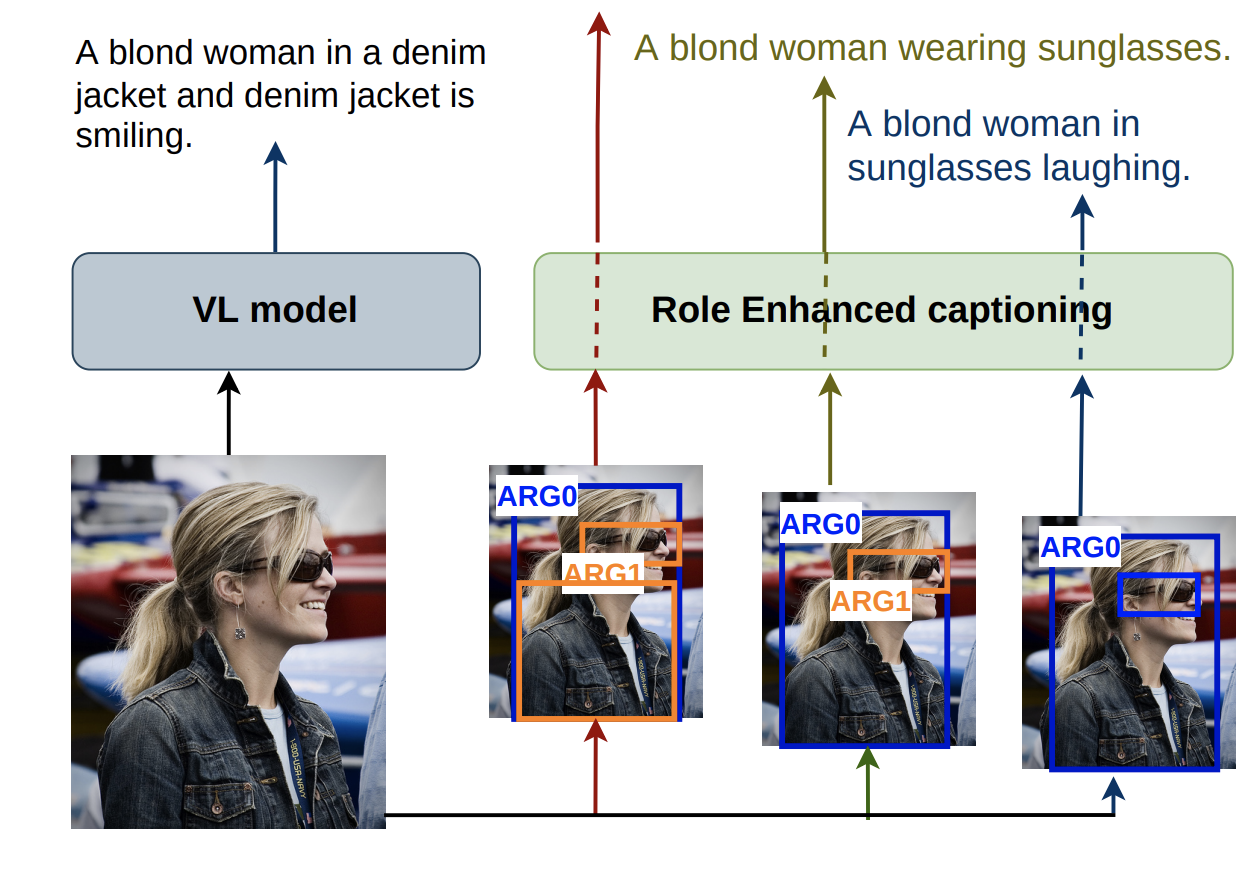 ReCAP: Semantic Role Enhanced Caption GenerationAbhidip Bhattacharyya, Martha Palmer, and Christoffer HeckmanIn Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), May 2024
ReCAP: Semantic Role Enhanced Caption GenerationAbhidip Bhattacharyya, Martha Palmer, and Christoffer HeckmanIn Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), May 2024Even though current vision language (V+L) models have achieved success in generating image captions, they often lack specificity and overlook various aspects of the image. Additionally, the attention learned through weak supervision operates opaquely and is difficult to control. To address these limitations, we propose the use of semantic roles as control signals in caption generation. Our hypothesis is that, by incorporating semantic roles as signals, the generated captions can be guided to follow specific predicate argument structures. To validate the effectiveness of our approach, we conducted experiments using data and compared the results with a baseline model VL-BART(CITATION). The experiments showed a significant improvement, with a gain of 45% in Smatch score (Standard NLP evaluation metric for semantic representations), demonstrating the efficacy of our approach. By focusing on specific objects and their associated semantic roles instead of providing a general description, our framework produces captions that exhibit enhanced quality, diversity, and controllability.
@inproceedings{bhattacharyya-etal-2024-recap, title = {{R}e{CAP}: Semantic Role Enhanced Caption Generation}, author = {Bhattacharyya, Abhidip and Palmer, Martha and Heckman, Christoffer}, editor = {Calzolari, Nicoletta and Kan, Min-Yen and Hoste, Veronique and Lenci, Alessandro and Sakti, Sakriani and Xue, Nianwen}, booktitle = {Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)}, month = may, year = {2024}, address = {Torino, Italia}, publisher = {ELRA and ICCL}, url = {https://aclanthology.org/2024.lrec-main.1191}, pages = {13633--13649}, }
2023
-
 CRAPES:Cross-modal Annotation Projection for Visual Semantic Role LabelingAbhidip Bhattacharyya, Martha Palmer, and Christoffer HeckmanIn The 12th Joint Conference on Lexical and Computational Semantics, Co-located with ACL, Jul 2023
CRAPES:Cross-modal Annotation Projection for Visual Semantic Role LabelingAbhidip Bhattacharyya, Martha Palmer, and Christoffer HeckmanIn The 12th Joint Conference on Lexical and Computational Semantics, Co-located with ACL, Jul 2023@inproceedings{crapes, title = {CRAPES:Cross-modal Annotation Projection for Visual Semantic Role Labeling}, author = {Bhattacharyya, Abhidip and Palmer, Martha and Heckman, Christoffer}, booktitle = {The 12th Joint Conference on Lexical and Computational Semantics, Co-located with ACL}, month = jul, year = {2023}, address = {Toronto, Canada}, publisher = {Association for Computational Linguistics}, } -
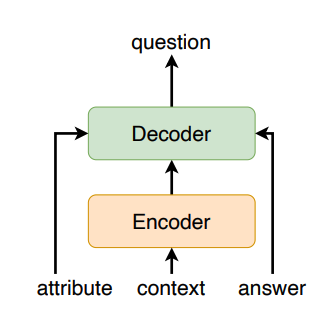 Comparing Neural Question Generation Architectures for Reading ComprehensionE. Margaret Perkoff, Abhidip Bhattacharyya, Jon Cai, and 1 more authorIn Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023), Jul 2023
Comparing Neural Question Generation Architectures for Reading ComprehensionE. Margaret Perkoff, Abhidip Bhattacharyya, Jon Cai, and 1 more authorIn Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023), Jul 2023In recent decades, there has been a significant push to leverage technology to aid both teachers and students in the classroom. Language processing advancements have been harnessed to provide better tutoring services, automated feedback to teachers, improved peer-to-peer feedback mechanisms, and measures of student comprehension for reading. Automated question generation systems have the potential to significantly reduce teachers’ workload in the latter. In this paper, we compare three differ- ent neural architectures for question generation across two types of reading material: narratives and textbooks. For each architecture, we explore the benefits of including question attributes in the input representation. Our models show that a T5 architecture has the best overall performance, with a RougeL score of 0.536 on a narrative corpus and 0.316 on a textbook corpus. We break down the results by attribute and discover that the attribute can improve the quality of some types of generated questions, including Action and Character, but this is not true for all models.
@inproceedings{perkoff-etal-2023-comparing, title = {Comparing Neural Question Generation Architectures for Reading Comprehension}, author = {Perkoff, E. Margaret and Bhattacharyya, Abhidip and Cai, Jon and Cao, Jie}, booktitle = {Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023)}, month = jul, year = {2023}, address = {Toronto, Canada}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.bea-1.47}, pages = {556--566}, }
2022
-
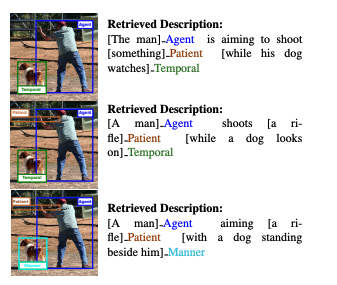 Aligning Images and Text with Semantic Role Labels for Fine-Grained Cross-Modal UnderstandingAbhidip Bhattacharyya, Cecilia Mauceri, Martha Palmer, and 1 more authorIn Proceedings of the Thirteenth Language Resources and Evaluation Conference, Jun 2022
Aligning Images and Text with Semantic Role Labels for Fine-Grained Cross-Modal UnderstandingAbhidip Bhattacharyya, Cecilia Mauceri, Martha Palmer, and 1 more authorIn Proceedings of the Thirteenth Language Resources and Evaluation Conference, Jun 2022As vision processing and natural language processing continue to advance, there is increasing interest in multimodal applications, such as image retrieval, caption generation, and human-robot interaction. These tasks require close alignment between the information in the images and text. In this paper, we present a new multimodal dataset that combines state of the art semantic annotation for language with the bounding boxes of corresponding images. This richer multimodal labeling supports cross-modal inference for applications in which such alignment is useful. Our semantic representations, developed in the natural language processing community, abstract away from the surface structure of the sentence, focusing on specific actions and the roles of their participants, a level that is equally relevant to images. We then utilize these representations in the form of semantic role labels in the captions and the images and demonstrate improvements in standard tasks such as image retrieval. The potential contributions of these additional labels is evaluated using a role-aware retrieval system based on graph convolutional and recurrent neural networks. The addition of semantic roles into this system provides a significant increase in capability and greater flexibility for these tasks, and could be extended to state-of-the-art techniques relying on transformers with larger amounts of annotated data.
@inproceedings{bhattacharyya-etal-2022-aligning, title = {Aligning Images and Text with Semantic Role Labels for Fine-Grained Cross-Modal Understanding}, author = {Bhattacharyya, Abhidip and Mauceri, Cecilia and Palmer, Martha and Heckman, Christoffer}, booktitle = {Proceedings of the Thirteenth Language Resources and Evaluation Conference}, month = jun, year = {2022}, address = {Marseille, France}, publisher = {European Language Resources Association}, url = {https://aclanthology.org/2022.lrec-1.528}, pages = {4944--4954}, }
2020
-
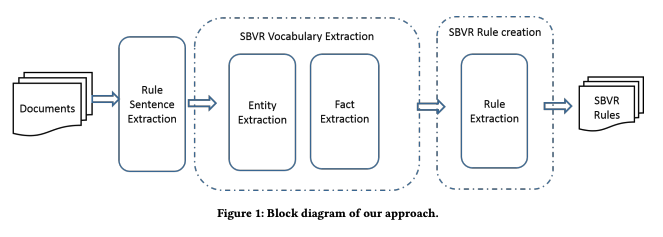 An Approach to Mine SBVR Vocabularies and Rules from Business DocumentsPavan Kumar Chittimalli, Chandan Prakash, Ravindra Naik, and 1 more authorIn Proceedings of the 13th Innovations in Software Engineering Conference on Formerly Known as India Software Engineering Conference, Jun 2020
An Approach to Mine SBVR Vocabularies and Rules from Business DocumentsPavan Kumar Chittimalli, Chandan Prakash, Ravindra Naik, and 1 more authorIn Proceedings of the 13th Innovations in Software Engineering Conference on Formerly Known as India Software Engineering Conference, Jun 2020Enterprises model the behavior of their business to prepare a communication standard for business analysts and to specify requirements to Information Technology (IT) people. The communication gap between IT group and business analysts, who lie on the opposite end of the business spectrum exists due to the different terminologies used in their respective fields regarding the same context. This gap has led to major software failures which prompted the OMG group has come up with a new standard - Semantic of Business Vocabulary and Business Rules (SBVR). Declarative models are provided by SBVR to represent Business Vocabulary and Business Rules which can be understood by everyone working throughout the business spectrum. Each business is governed by business rules which are constrained by the regulation policy set up by the policy guidelines of the organization and government regulations set up on the organization. Business rules are specified in documents like user guides, requirement documents, terms and conditions, do’s and don’ts. Typically a Business Analyst interprets the document and manually extracts rules based on his understanding which leads to potential discrepancies, ambiguities and quality issues in the software system. To minimize such errors, in this paper we present an unsupervised approach to automatically extract SBVR vocabularies and rules from domain-specific business documents. We also present our initial results and comparative study with our earlier approach.
@inproceedings{10.1145/3385032.3385046, author = {Chittimalli, Pavan Kumar and Prakash, Chandan and Naik, Ravindra and Bhattacharyya, Abhidip}, title = {An Approach to Mine SBVR Vocabularies and Rules from Business Documents}, year = {2020}, isbn = {9781450375948}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3385032.3385046}, doi = {10.1145/3385032.3385046}, booktitle = {Proceedings of the 13th Innovations in Software Engineering Conference on Formerly Known as India Software Engineering Conference}, articleno = {12}, numpages = {11}, keywords = {Text Mining, Business Rules Extraction, Rule Components, SBVR, Natural Language Processing, Rule Document}, location = {Jabalpur, India}, series = {ISEC 2020}, }
2019
-
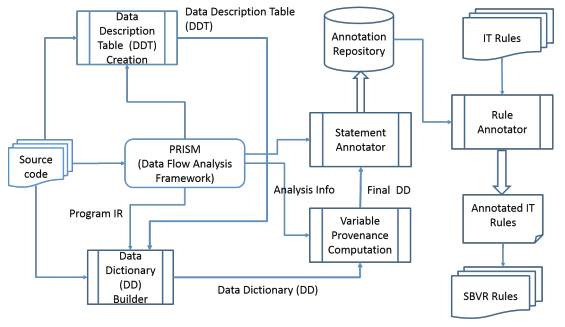 SBVR-Based Business Rule Creation for Legacy Programs Using Variable ProvenancePavan Kumar Chittimalli, and Abhidip BhattacharyyaIn Proceedings of the 12th Innovations on Software Engineering Conference (Formerly Known as India Software Engineering Conference), Jun 2019
SBVR-Based Business Rule Creation for Legacy Programs Using Variable ProvenancePavan Kumar Chittimalli, and Abhidip BhattacharyyaIn Proceedings of the 12th Innovations on Software Engineering Conference (Formerly Known as India Software Engineering Conference), Jun 2019Functionality of a software system that implements business operations can be captured using business processes and rules. To understand the ’as-is’ processes and rules, the source-code is arguably the best source of knowledge. We present a novel method that combines program analysis and domain knowledge to create the descriptions for "IT rules", as a critical step towards extracting business rules automatically. We introduce and use the concept of ’variable provenance’ to propagate the domain descriptions into the source code to create Semantics of Business Vocabularies and Rules (SBVR) rules. In our experiments on sample, near-real-life systems, we could successfully annotate very large percentage (> 90%) of IT rules and enable to create SBVR rules. We present and describe the ProgAnnotator tool which is based on variable provenance and generates descriptions for IT rules in the source code and subsequently create SBVR rules automatically.
@inproceedings{10.1145/3299771.3299786, author = {Chittimalli, Pavan Kumar and Bhattacharyya, Abhidip}, title = {SBVR-Based Business Rule Creation for Legacy Programs Using Variable Provenance}, year = {2019}, isbn = {9781450362153}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3299771.3299786}, doi = {10.1145/3299771.3299786}, booktitle = {Proceedings of the 12th Innovations on Software Engineering Conference (Formerly Known as India Software Engineering Conference)}, articleno = {16}, numpages = {11}, keywords = {Variable Provenance, Business Rule Extraction, Rule Annotation, SBVR, Static Program Analysis}, location = {Pune, India}, series = {ISEC'19}, }
2018
-
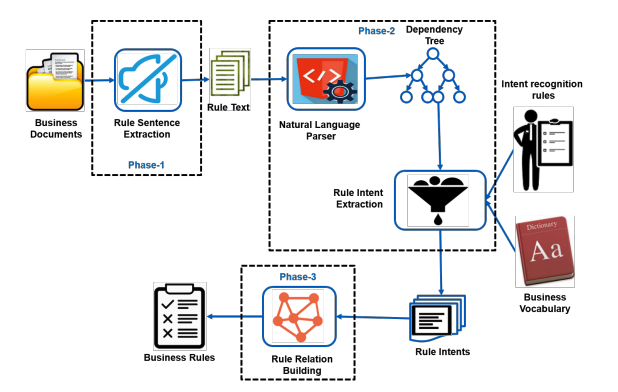 Relation Identification in Business Rules for Domain-Specific DocumentsAbhidip Bhattacharyya, Pavan Kumar Chittimalli, and Ravindra NaikIn Proceedings of the 11th Innovations in Software Engineering Conference, Jun 2018
Relation Identification in Business Rules for Domain-Specific DocumentsAbhidip Bhattacharyya, Pavan Kumar Chittimalli, and Ravindra NaikIn Proceedings of the 11th Innovations in Software Engineering Conference, Jun 2018This paper focuses on an approach to mine business rules from documents and facilitates a methodology to represent them in a formal notation. Businesses are operated abiding by some rules and complying with respect to regulation and guidelines. The business rules are often written using English in operating procedures, terms and conditions, and various other supporting documents. The manual analysis of these rules for activities like impact analysis, maintenance, business transformation leads to potential discrepancies, ambiguities, and quality issues. In this paper, we discuss our approach of mining relations among the rule intents (atomic facts) defined for business rules. We also present our preliminary studies on a couple of openly available documents.
@inproceedings{10.1145/3172871.3172884, author = {Bhattacharyya, Abhidip and Chittimalli, Pavan Kumar and Naik, Ravindra}, title = {Relation Identification in Business Rules for Domain-Specific Documents}, year = {2018}, isbn = {9781450363983}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3172871.3172884}, doi = {10.1145/3172871.3172884}, booktitle = {Proceedings of the 11th Innovations in Software Engineering Conference}, articleno = {14}, numpages = {5}, keywords = {Natural Language Processing, Maximum Entropy, Document Mining, Business Rule Extraction}, location = {Hyderabad, India}, series = {ISEC '18}, }
2017
- An Approach to Mine Business Rule Intents from Domain-Specific DocumentsAbhidip Bhattacharyya, Pavan Kumar Chittimalli, and Ravindra NaikIn Proceedings of the 10th Innovations in Software Engineering Conference, Jun 2017
An enterprise system enables business by providing various services that are guided by set of well-defined processes, and adhere to certain business rules and constraints. The business rules are usually written using English in operating procedures, terms and conditions, and various other supporting documents. For implementing the business rules in a software system, or expressing them as UML use-case specifications, analysts manually interpret the documents, leading to potential discrepancies, ambiguities, and quality issues in the software system that can be resolved only after testing.To minimize such errors, we propose a novel method to mine the documents automatically to extract the fundamental atomic facts in every sentence - called as business rule intents. We adopt dependency tree parser to parse the rule sentences and extract rule intents from them. Our experiments using few publicly available sample documents in the financial domain yielded very promising results, where rule intents extraction produced an average precision of 78% and recall of 80%.
@inproceedings{10.1145/3021460.3021470, author = {Bhattacharyya, Abhidip and Chittimalli, Pavan Kumar and Naik, Ravindra}, title = {An Approach to Mine Business Rule Intents from Domain-Specific Documents}, year = {2017}, isbn = {9781450348560}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3021460.3021470}, doi = {10.1145/3021460.3021470}, booktitle = {Proceedings of the 10th Innovations in Software Engineering Conference}, pages = {96–106}, numpages = {11}, location = {Jaipur, India}, series = {ISEC '17}, }